2020/06/23 - [파이썬/주식] - Python으로 S-RIM 계산 적정주가 계산하기
Python으로 S-RIM 계산 적정주가 계산하기
http://www.yes24.com/Product/Goods/86017987?Acode=101 재무제표 모르면 주식투자 절대로 하지마라 재무제표가 정말 주식투자에 도움이 될까?출발부터 다른 ‘투자자를 위한’ 맞춤형 재무제표 읽기 비법!2016
jsp-dev.tistory.com
python으로 s-rim 계산하는 포스팅에서 기준이 되는 bbb- 기업 5년 금리를 하드코딩해서 사용했는데
포스팅 시점이 그렇게 오래 되지 않았음에도 볼 때마다 벌써 몇번째 바뀐건지 모를 정도로 많이 바뀌었다.
큰 차이는 없지만 보다 정확하게 하기 위해서 웹 크롤링을 이용하게 되었는데
그 과정을 기록
우선 우리가 눈으로 확인할 수 있는 페이지 url (www.kisrating.co.kr/ratingsStatistics/statics_spread.do#)
여기서

이 테이블에 저 부분
즉 행은 BBB-가 위치한 부분이고 열은 5년에 해당하는 값 7.90를 가져오면 된다
크롬기준 F12를 누르거나 저 부분에서 마우스 우클릭 > 검사를 눌러 html를 본다.
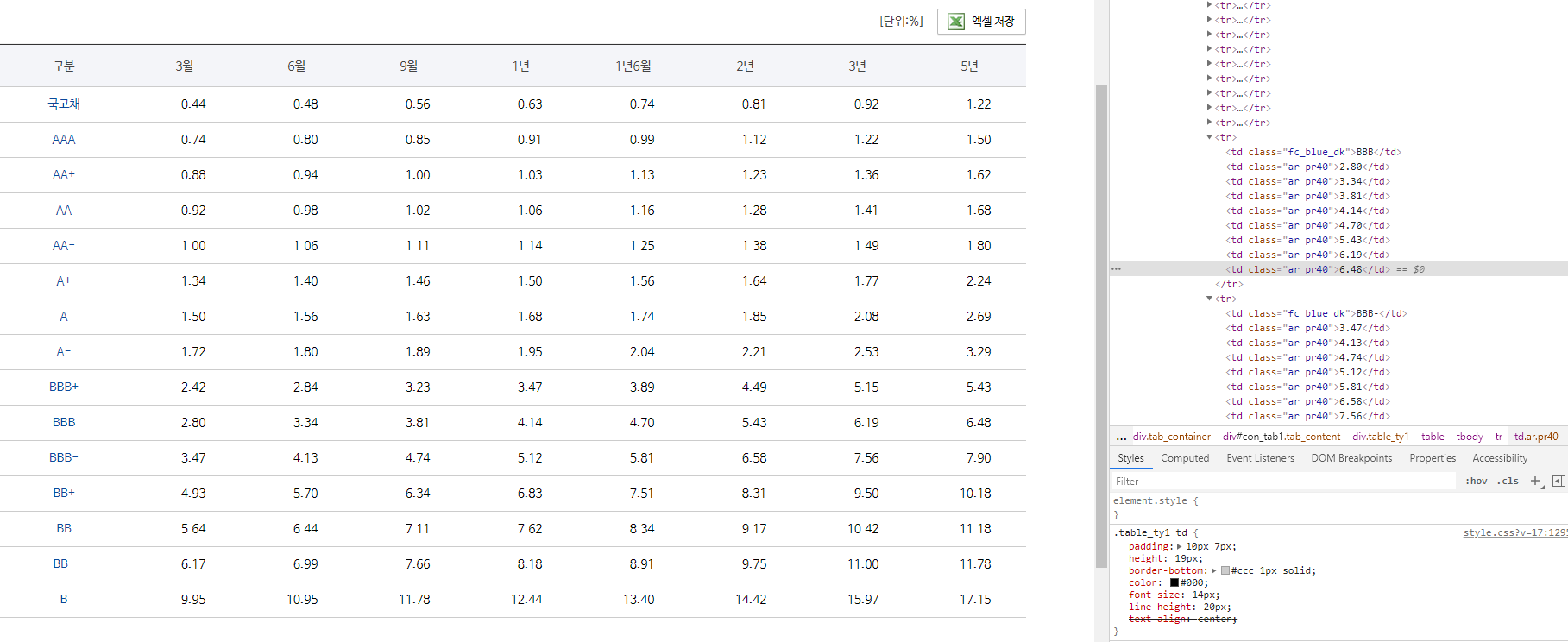
이렇게 확인해보면 저 셀에 해당하는 값을 특정할 수는 없어보인다
그 이유는 table 안에 있는 7.90를 보면 다른 셀 값들과 봐서 별다른 특징이 없어 특정지어 바로 가져올 수가 없다.
따라서 저 테이블을 전체 크롤링하고 값을 뽑아내본다

테이블명은 table_ty1이다.
따라서 python으로 bs4와 requests를 이용해 간단히 가져오는 소스를 바로 첨부하면
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.kisrating.com/ratingsStatistics/statics_spread.do'
res = requests.get(url)
page_soup = BeautifulSoup(res.text, 'lxml')
table = page_soup.select_one('div.table_ty1')
# html -> 문자열
table_html = str(table)
# pandas의 read_html로 테이블 정보 읽기
table_df= pd.read_html(table_html)[0]
print(type(table_df))
table_df.set_index('구분', inplace=True)
print(table_df)
interest_rate = table_df.loc['BBB-', '5년']
print(interest_rate , type(interest_rate))
이렇게 된다.
table_df 부분에는 이런 값들이 들어 있다.
따라서 bbb- 5년 금리가 아니더라도 다른 것도 가져와 사용할 수 있다.
구분 3월 6월 9월 1년 1년6월 2년 3년 5년
0 국고채 0.44 0.48 0.56 0.63 0.74 0.81 0.92 1.22
1 AAA 0.74 0.80 0.85 0.91 0.99 1.12 1.22 1.50
2 AA+ 0.88 0.94 1.00 1.03 1.13 1.23 1.36 1.62
3 AA 0.92 0.98 1.02 1.06 1.16 1.28 1.41 1.68
4 AA- 1.00 1.06 1.11 1.14 1.25 1.38 1.49 1.80
5 A+ 1.34 1.40 1.46 1.50 1.56 1.64 1.77 2.24
6 A 1.50 1.56 1.63 1.68 1.74 1.85 2.08 2.69
7 A- 1.72 1.80 1.89 1.95 2.04 2.21 2.53 3.29
8 BBB+ 2.42 2.84 3.23 3.47 3.89 4.49 5.15 5.43
9 BBB 2.80 3.34 3.81 4.14 4.70 5.43 6.19 6.48
10 BBB- 3.47 4.13 4.74 5.12 5.81 6.58 7.56 7.90
11 BB+ 4.93 5.70 6.34 6.83 7.51 8.31 9.50 10.18
12 BB 5.64 6.44 7.11 7.62 8.34 9.17 10.42 11.18
13 BB- 6.17 6.99 7.66 8.18 8.91 9.75 11.00 11.78
14 B 9.95 10.95 11.78 12.44 13.40 14.42 15.97 17.15
기준 url로 부터 div.table_ty1를 전체 갖고 와서 dataframe으로 만든 다음 채권등급을 기준으로 인덱스를 만들어 접근하기 쉽게 만들어서 바로 가져오도록 했다
print 함수 및 주석 빼면 진짜 몇줄안되는 코딩으로 쉽게 웹크롤링할 수 있는 파이썬 짱이다.
그동안 하드코딩으로 대충 박아두고(?) 사용했던 금리값을 조금이라도 더 정확히 하기 위해서 크롤링으로 바꿨는데
큰 일은 아니지만 그래도 하길 잘한 것 같다는 생각이 든다.
제 블로그에 방문해주셔서 감사합니다.
좋아요, 댓글은 제가 글을 쓰는데 큰 힘이 됩니다.
아래는 쿠팡 링크이고 쿠팡 파트너스 활동을 통해 일정 수익이 발생할 수 있음을 알려 드립니다.
'파이썬 > 주식' 카테고리의 다른 글
| 주식의 적정가격이 궁금하다면? 적정가격 계산기 (S-RIM) (0) | 2022.11.22 |
|---|---|
| [공지] 쉽게 따라 만드는 파이썬 주식 자동매매 시스템 출간 (197) | 2021.10.14 |
| Python으로 S-RIM 계산 적정주가 계산하기 (9) | 2020.06.23 |
| Python으로 보통주, 우선주 괴리율을 이용한 투자전략 - 2 (0) | 2020.06.06 |
| Python으로 보통주, 우선주 괴리율을 이용한 투자전략 - 1 (0) | 2020.06.06 |




댓글