오늘은 BeautifulSoup4으로 finace.naver.com 에 있는 기업의 재무정보를 크롤링하는 법을 포스팅해보겠습니다.
준비물 : BeautifulSoup4, lxml
크롤링할 대상은 기업마다 존재하는 아래 기업실적분석 정보입니다.
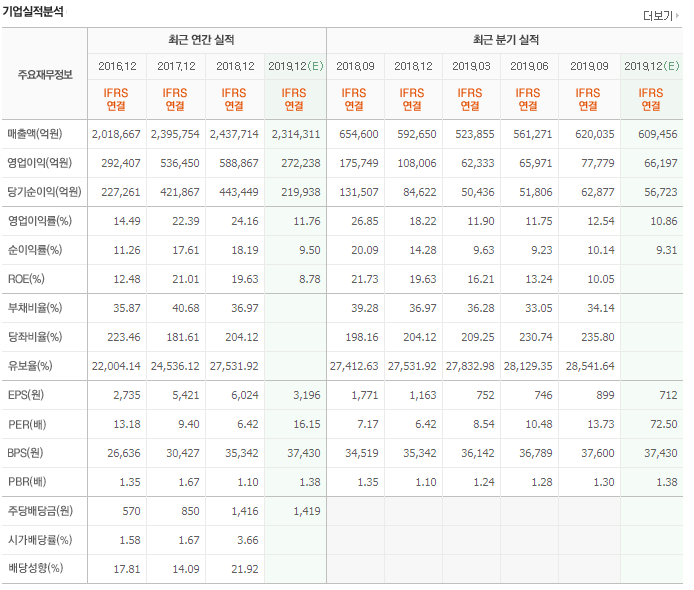
BeautifulSoup을 이용해서 위의 정보를 받아오려면 크롤링할 페이지의 URL그리고 긁어올 부분의 html tag를 알아야 합니다. 위 테이블의 tag를 보기 위해서는 크롬기준 F12를 눌러 해당 tag의 class를 확인합니다.
확인해보니 div tag의 class명은 cop_analysis입니다.
이 정보를 바탕으로 크롤링 해보겠습니다.

import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
BASE_URL = 'https://finance.naver.com'
def crawl(code):
req = requests.get(BASE_URL + '/item/main.nhn?code=' + code)
page_soup = BeautifulSoup(req.text, 'lxml')
finance_html = page_soup.select_one('div.cop_analysis')req로 받아온 정보를 BeautifulSoup을 사용해 parsing했습니다. 그 중에서 div tag로 된 classname = 'cop_analysis'를 긁어옵니다.
finace_html을 확인해보면 우리가 필요한 테이블 정보가 들어가 있습니다.
이 정보들을 이쁘게 꺼내보겠습니다.
따로 구분 지어야 할 정보는 크게 세가지입니다.
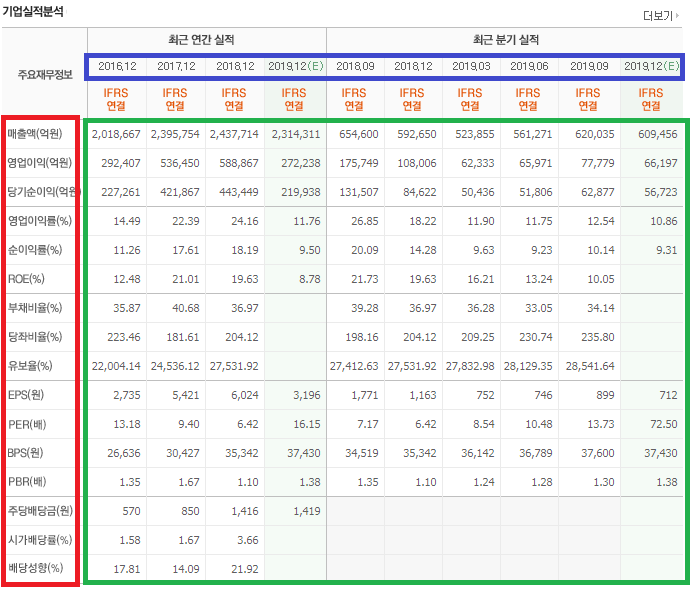
빨간색으로 표시한 부분 index로 사용할 부분들이고 파란색으로 표시한 날짜정보는 column으로 사용하겠습니다.
그리고 table 안에 있는 초록색 부분(td tag)는 이에 해당하는 정보들입니다.
이 들을 각각 구분 지어 보겠습니다.
def crawl(code):
req = requests.get(BASE_URL + '/item/main.nhn?code=' + code)
page_soup = BeautifulSoup(req.text, 'lxml')
finance_html = page_soup.select_one('div.cop_analysis')
th_data = [item.get_text().strip() for item in finance_html.select('thead th')]
annual_date = th_data[3:7] # ['2016.12', '2017.12', '2018.12', '2019.12(E)']
quarter_date = th_data[7:13] # ['2018.09', '2018.12', '2019.03', '2019.06', '2019.09', '2019.12(E)']첫번째로 날짜 정보를 뽑아내겠습니다. 이 정보들은 table의 thead 밑에 각각 th에 해당합니다.
finance_html에서 thead 부분 중 th를 뽑아낸 th_data에는 날짜정보가 순서대로 들어가 있으나 이외에도 필요 없는 정보들이 들어가 있습니다. th_data 안에만 보면 이렇게 되어있습니다.
['주요재무정보', '최근 연간 실적', '최근 분기 실적', '2016.12', '2017.12', '2018.12', '2019.12(E)', '201809', '2018.12', '2019.03', '2019.06', '2019.09', '2019.12(E)', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결', 'IFRS연결']
이중 필요한 정보들(annual_date, quarter_date)만 걸러내겠습니다.
def crawl(code):
req = requests.get(BASE_URL + '/item/main.nhn?code=' + code)
page_soup = BeautifulSoup(req.text, 'lxml')
finance_html = page_soup.select_one('div.cop_analysis')
th_data = [item.get_text().strip() for item in finance_html.select('thead th')]
annual_date = th_data[3:7] # ['2016.12', '2017.12', '2018.12', '2019.12(E)']
quarter_date = th_data[7:13] # ['2018.09', '2018.12', '2019.03', '2019.06', '2019.09', '2019.12(E)']
finance_index = [item.get_text().strip() for item in finance_html.select('th.h_th2')][3:]
# ['주요재무정보', '최근 연간 실적', '최근 분기 실적', '매출액', '영업이익', '당기순이익', '영업이익률', '순이익률', 'ROE(지배주주)', '부채비율', '당좌비율', '유보율', 'EPS(원)', 'PER(배)', 'BPS(원)', 'PBR(배)', '주당배당금(원)', '시가배당률(%)', '배당성향(%)']
finance_data = [item.get_text().strip() for item in finance_html.select('td')]
다음은 각각이 숫자들이 무엇을 의미하는지 나타내는 index(ex 매출액, 영업이익)을 뽑아내겠습니다.
주요재무정보 항목들을 나타냅니다. 이 부분은 finance_html 중 classname='h_th2'인 th들입니다.
하지만 전부를 뽑아내보면
['주요재무정보', '최근 연간 실적', '최근 분기 실적', '매출액', '영업이익', '당기순이익', '영업이익률', '순이익률', 'ROE(지배주주)', '부채비율', '당좌비율', '유보율', 'EPS(원)', 'PER(배)', 'BPS(원)', 'PBR(배)', '주당배당금(원)', '시가배당률(%)', '배당성향(%)']
이런 정보가 들어가 있습니다. 마찬가지로 앞에 필요없는 부분을 제외하고 index에 담겠습니다.
다음은 data라는 항목으로 table의 td(숫자)들을 finance_data에 담아넣겠습니다.
이렇게 넣은 finance_data는 일차원 형태이나 실제 테이블 구조처럼 N x N으로 바꿔줘야합니다.
이 작업까지 한 코드입니다.
def crawl(code):
req = requests.get(BASE_URL + '/item/main.nhn?code=' + code)
page_soup = BeautifulSoup(req.text, 'lxml')
finance_html = page_soup.select_one('div.cop_analysis')
th_data = [item.get_text().strip() for item in finance_html.select('thead th')]
annual_date = th_data[3:7] # ['2016.12', '2017.12', '2018.12', '2019.12(E)']
quarter_date = th_data[7:13] # ['2018.09', '2018.12', '2019.03', '2019.06', '2019.09', '2019.12(E)']
finance_index = [item.get_text().strip() for item in finance_html.select('th.h_th2')][3:] # ['주요재무정보', '최근 연간 실적', '최근 분기 실적', '매출액', '영업이익', '당기순이익', '영업이익률', '순이익률', 'ROE(지배주주)', '부채비율', '당좌비율', '유보율', 'EPS(원)', 'PER(배)', 'BPS(원)', 'PBR(배)', '주당배당금(원)', '시가배당률(%)', '배당성향(%)']
finance_data = [item.get_text().strip() for item in finance_html.select('td')]
finance_data = np.array(finance_data)
finance_data.resize(len(finance_index), 10)resize를 통해 (index의 개수) x (10, 연, 분기 날짜만큼)으로 나눴습니다.
이를 pandas DataFrame에 담아 넣고 연간, 분기로 나눠서 return하는 crawl함수를 완성합니다.
이 부분을 모두 완성하여 "삼성전자=005930" 재무정보를 크롤링하는 전체 소스입니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
BASE_URL = 'https://finance.naver.com'
def crawl(code):
req = requests.get(BASE_URL + '/item/main.nhn?code=' + code)
page_soup = BeautifulSoup(req.text, 'lxml')
finance_html = page_soup.select_one('div.cop_analysis')
th_data = [item.get_text().strip() for item in finance_html.select('thead th')]
annual_date = th_data[3:7] # ['2016.12', '2017.12', '2018.12', '2019.12(E)']
quarter_date = th_data[7:13] # ['2018.09', '2018.12', '2019.03', '2019.06', '2019.09', '2019.12(E)']
finance_index = [item.get_text().strip() for item in finance_html.select('th.h_th2')][3:] # ['주요재무정보', '최근 연간 실적', '최근 분기 실적', '매출액', '영업이익', '당기순이익', '영업이익률', '순이익률', 'ROE(지배주주)', '부채비율', '당좌비율', '유보율', 'EPS(원)', 'PER(배)', 'BPS(원)', 'PBR(배)', '주당배당금(원)', '시가배당률(%)', '배당성향(%)']
finance_data = [item.get_text().strip() for item in finance_html.select('td')]
finance_data = np.array(finance_data)
finance_data.resize(len(finance_index), 10)
finance_date = annual_date + quarter_date
finance = pd.DataFrame(data=finance_data[0:, 0:], index=finance_index, columns=finance_date)
annual_finance = finance.iloc[:, :4]
quarter_finance = finance.iloc[:, 4:]
return finance,annual_finance,quarter_finance
finace,annual,quarter = crawl('005930')
print(quarter.iloc[5])
이름은 crawl이지만 가져와서 자르고 나누는 작업을 모두 다하는 함수를 완성했습니다.ㅎㅎ
전체 정보인 finace 및 연간, 분기 정보를 다 잘라서 반환하도록 했습니다.
여기서 분기의 5번째 행 (ROE)을 출력해보는 print(quarter.iloc[5])을 통해 잘 가져왔음을 알 수 있습니다.
원래 이 기업정보의 원천은 전자공시시스템(dart)을 통하므로 dart를 크롤링해서 사용하는 것이 더 많은 정보를 볼 수 있겠으나 이 포스팅에서는 간략한 정보를 이쁘게 담은 Naver finace를 크롤링해보았습니다.
감사합니다.
** 제 블로그에 와주셔서 감사합니다.
재밌게 보셨다면 좋아요, 댓글은 저에게 큰 힘이 됩니다!
감사합니다!
'파이썬 > 주식' 카테고리의 다른 글
| Python으로 모멘텀 전략 구현, Python Momentum Strategy (2) | 2019.12.01 |
|---|---|
| Python, multiprocessing으로 좀 더 빠른 Naver Finance 크롤러 만들기 / multiprocessing crawling (0) | 2019.11.27 |
| Python으로 종목코드(코스피/코스닥) 엑셀로 저장/읽기 (3) | 2019.11.17 |
| Python으로 보조지표 MACD 구하기 MACD Oscillator 구하기 (0) | 2019.11.10 |
| Python으로 RSI(Relative Strength Index) 구하기 (8) | 2019.11.06 |




댓글