이번에는 Python을 이용해 모멘텀/가치 평가 주식을 골라내기 포스팅입니다. 이번 편은 이전 제 포스팅인
이글을 기초로 하였으며 제가 좋아하는 강환국님의 유튜브 에서 아이디어를 얻었습니다.
이 글에서 하고자 하는 것은 Python을 이용해 KOSPI 상장 주식 중 모멘텀과 가치평가(PER,PBR)을 이용해 추천 종목을 선정하는 것입니다.
1. 준비물
먼저 KOSPI 주가 정보가 필요합니다.
FinanceDataReader을 이용해 KOSPI 주가를 얻어와 datas.xlsx로 저장하겠습니다.
이 정보는 1달/1년 모멘텀을 이용하는데 사용할 예정입니다.
generateData.py
import pandas as pd
import FinanceDataReader as fdr
from time import time
from concurrent.futures import ProcessPoolExecutor
df_krx = fdr.StockListing('KRX')
df_krx['SymbolName'] = df_krx['Symbol'] + df_krx['Name']
codes = df_krx['SymbolName']
def getPrice(code):
df_price = fdr.DataReader(code[:6], '2018-12-01', '2019-12-22') # 주가 가져오기
df_price = df_price[['Close']]
df_price.columns = [code[6:]]
return df_price
if __name__ == '__main__':
start = time()
pool = ProcessPoolExecutor(max_workers=10)
results = list(pool.map(getPrice,codes))
stocks = pd.concat(results, axis=1)
end = time()
print(end-start)
stocks.to_excel('datas.xlsx')
다음은 재무정보를 얻어오는 것입니다.
이전 제 포스팅에 정리가 되어 있는 소스이지만 재첨부하겠습니다.
crawlerNaverFSummary.py
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
BASE_URL='https://finance.naver.com/sise/sise_market_sum.nhn?sosok='
KOSPI_CODE = 0
KOSDAK_CODE = 1
START_PAGE = 1
fields = []
def main(code):
# total_page을 가져오기 위한 requests
res = requests.get(BASE_URL + str(code) + "&page=" + str(START_PAGE))
page_soup = BeautifulSoup(res.text, 'lxml')
# total_page 가져오기
total_page_num = page_soup.select_one('td.pgRR > a')
total_page_num = int(total_page_num.get('href').split('=')[-1])
#가져올 수 있는 항목명들을 추출
ipt_html = page_soup.select_one('div.subcnt_sise_item_top')
global fields
fields = [item.get('value') for item in ipt_html.select('input')]
# page마다 정보를 긁어오게끔 하여 result에 저장
result = [crawl(code,str(page)) for page in range(1,total_page_num+1)]
# page마다 가져온 정보를 df에 하나로 합침
df = pd.concat(result, axis=0,ignore_index=True)
# 엑셀로 내보내기
df.to_excel('NaverFinance.xlsx')
def crawl(code, page):
global fields
data = {'menu': 'market_sum',
'fieldIds': fields,
'returnUrl': BASE_URL + str(code) + "&page=" + str(page)}
# requests.get 요청대신 post 요청
res = requests.post('https://finance.naver.com/sise/field_submit.nhn', data=data)
page_soup = BeautifulSoup(res.text, 'lxml')
# 크롤링할 table html 가져오기
table_html = page_soup.select_one('div.box_type_l')
# Column명
header_data = [item.get_text().strip() for item in table_html.select('thead th')][1:-1]
# 종목명 + 수치 추출 (a.title = 종목명, td.number = 기타 수치)
inner_data = [item.get_text().strip() for item in table_html.find_all(lambda x:
(x.name == 'a' and
'tltle' in x.get('class', [])) or
(x.name == 'td' and
'number' in x.get('class', []))
)]
# page마다 있는 종목의 순번 가져오기
no_data = [item.get_text().strip() for item in table_html.select('td.no')]
number_data = np.array(inner_data)
# 가로 x 세로 크기에 맞게 행렬화
number_data.resize(len(no_data), len(header_data ))
# 한 페이지에서 얻은 정보를 모아 DataFrame로 만들어 리턴
df = pd.DataFrame(data=number_data, columns=header_data )
return df
main(KOSPI_CODE)
위 코드를 실행하면 NaverFinance.xlsx라는 파일이 생깁니다.
2. 모멘텀+가치 전략 수행
- datas.xlsx에는 주가 정보가 담겨 있습니다. 이를 통해 1달/1년 전 주가를 얻어올 예정입니다.
- NaverFinance.xlsx에는 PER, PBR과 같은 정보들이 있고 시가총액 기준 정렬이 되어 있습니다.
이를 바탕으로 datas에서 주가를 얻어올 예정입니다.
강환국님의 유튜브를 보시면 일일이 손으로 하는 과정 (ex, BPR구하려고 1/PBR 계산)을 코드로 만든 것입니다.
특별히 어려운 것은 없으며 나름 주석을 달아두었습니다.
유튜브와의 차이점은 강환국님은 가치평가로 순위를 매긴 다음 상위 종목들에 대해 모멘텀을 확인했으나
저는 가치평가로 순위를 매긴 다음에 (가치평가 순위 + 모멘텀 순위)를 이용해 최종 순위를 냈습니다.
#준비물1 가격정보 datas.xlsx
#준비물2 재무정보 NaverFinance.xlsx
import pandas as pd
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
df_finance = pd.read_excel('NaverFinance.xlsx') # NaverFinance - 재무정보
df_price = pd.read_excel('datas.xlsx',index_col=0) # datas - 가격정보 with 날짜정보 그대로
MONTH_AGO = datetime(2019,12,20)+relativedelta(months=-1) # 1달전 주가구하기, 그냥 오늘 날로 하려면 datetime.today() + relativedelta(months=-1)
MONTH_AGO = MONTH_AGO.strftime('%Y-%m-%d')
YEAR_AGO = datetime(2019,12,20)+relativedelta(years=-1) # 1년전 주가구하기, 그냥 오늘 날로 하려면 datetime.today()+relativedelta(years=-1)
YEAR_AGO = YEAR_AGO.strftime('%Y-%m-%d')
price_month_ago =[]
price_year_ago =[]
for index, row in df_finance.iterrows():
name = row['종목명']
if name in df_price.columns:
price_month_ago.append(df_price.loc[MONTH_AGO, name] ) # 준비물인 datas에서 1달 전 주가 구하기
price_year_ago.append(df_price.loc[YEAR_AGO, name]) # 준비물인 datas에서 1년 전 주가 구하기
else :
# datas에서 종목이 존재하지 않는 경우(우선주, ETF 등은 없음)가 있으므로 제외
price_month_ago.append(0)
price_year_ago.append(0)
df_finance['price_month_ago'] = price_month_ago # 1달 전 주가를 구해서 새로운 COLUMN으로 추가
df_finance['price_year_ago'] = price_year_ago # 1년 전 주가를 구해서 새로운 COLUMN으로 추가
df_finance =df_finance[df_finance['price_month_ago']!= 0] # 기준의 가격이 0이 아닌 종목만(우선주 등 없는 데이터 제외)
df_finance = df_finance.reset_index(drop=True)
df_finance = df_finance.loc[:200] # 시총 상위 200개만 추출, df_finance의 원천인 NaverFinance.xlsx은 원래 시총순 정렬이므로 순서대로 200개 자름
df_finance['BPR'] = 1/df_finance['PBR'].astype(float) # BPR = 1/PBR
df_finance['1/PER'] = 1/df_finance['PER'].str.replace(',', '').astype(float) # Per가 1000이 넘어 1,000인 형태가 존재하므로 replace 수행 후 type 변경
df_finance['RANK_BPR'] = df_finance['BPR'].rank(method='max', ascending=False) # BPR의 순위
df_finance['RANK_1/PER'] = df_finance['1/PER'].rank(method='max', ascending=False) # 1/PER의 순위
df_finance['RANK_VALUE'] = (df_finance['RANK_BPR'] + df_finance['RANK_1/PER'])/ 2 # 순위의 평균을 구함 > 가치평가 순위
df_finance = df_finance.sort_values(by=['RANK_VALUE']) # 가치평가 순위로 정렬
df_finance = df_finance.reset_index(drop=True)
df_finance = df_finance.loc[:75] # 가치평가로 상위 75개만 추출
# ----- 1차 가치평가 종료 -----
df_finance['현재가'] = df_finance['현재가'].str.replace(',', '').astype(float)
#1달 등락률 계산
df_finance['momentum_month'] = df_finance['현재가'] - df_finance['price_month_ago'] #오늘주가 - 1달 전 주가
df_finance['1달 등락률'] = (df_finance['현재가'] - df_finance['price_month_ago']) / df_finance['현재가']
#1년 등락률 계산
df_finance['momentum_year'] = df_finance['현재가'] - df_finance['price_year_ago'] #오늘주가 - 1년 전 주가
df_finance['1년 등락률'] = (df_finance['현재가'] - df_finance['price_year_ago']) / df_finance['현재가']
df_finance['FINAL_MOMENTUM'] = df_finance['1년 등락률'] - df_finance['1달 등락률'] # 1년 등락률 - 1달 등락률
df_finance['RANK_MOMENTUM'] = df_finance['FINAL_MOMENTUM'].rank(method='max', ascending=False) # 모멘텀의 순위
# ----- 2차 모멘텀평가 종료 -----
df_finance['FINAL_RANK'] = (df_finance['RANK_VALUE'] + df_finance['RANK_MOMENTUM'])/2 # 가치 순위와 모멘텀 순위의 합산
df_finance = df_finance.sort_values(by=['FINAL_RANK'], ascending=[True])
df_finance = df_finance.reset_index(drop=True)
df_finance.to_excel('momentum+value.xlsx') # 최종 선정된 주식들 목록
print(df_finance.head())
위의 코드를 실행하면 다음과 같습니다.
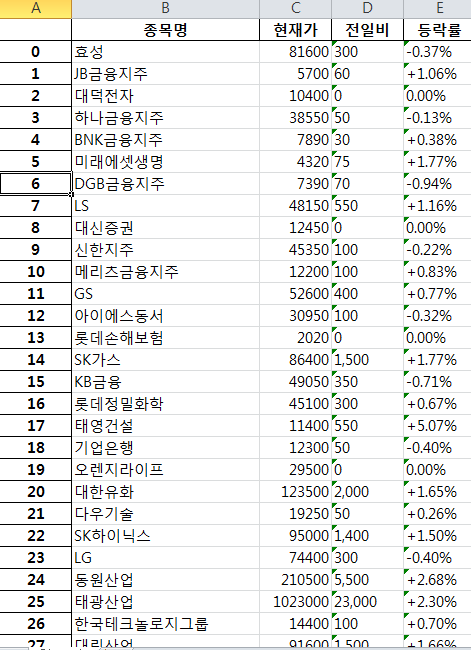
3. Comment
먼저 코드 상에 문제점으로는 '2019-12-20'의 1년 전인 '2018-12-20'이 주식 거래일이라 datas에 포함되어 있어서 계산이 가능했지만 주말이거나 휴일이었으면 datas에 존재하지 않아 찾지 못해 에러가 날 수 있습니다. 1달 전 계산도 마찬가지입니다( 코드 22,23 line) 이런 상황에 대한 처리가 있어야 합니다.
또 기존 데이터 컬럼들이 대체로 한글인데 제가 영어명 컬럼도 섞어 넣어 보기 불편하실 수도 있을 것 같습니다.
모멘텀+가치 전략을 이용해 종목을 추출해보았습니다.
결과를 보면 금융주들이 대체로 높은 순위에 있음을 알 수 있습니다.
그외로 1등인 효성은 1년 전쯤에 주가가 박살이 났었다 회복했기에 모멘텀에서 상당히 높은 점수를 얻었습니다.
물론 이렇게 추출한 종목들이 최고라고 할 수는 없지만 나름의 전략을 사요애 추출한 것들이니 어느 정도의 상승 확률을 가지고 있다고 볼 수 있을 것 같습니다.
Value and Momentum everywhere
같이 보시면 좋을 글
2021/02/10 - [파이썬/주식 자동매매] - 주식매매프로그램 개발 노하우, 소스를 담은 전자책이 발간되었습니다.
주식매매프로그램 개발 노하우, 소스를 담은 전자책이 발간되었습니다.
주식매매프로그램 개발 노하우에 관한 제 전자책이 발간되었습니다. https://kmong.com/gig/292764 주식매매프로그램, 쉽게 따라 만드는 노하우와 소스를 드립니다. | 36000원부터 시작 가능한 총 평 0개
jsp-dev.tistory.com
'파이썬 > 주식' 카테고리의 다른 글
| Python,Backtrader 다중 데이터 백테스팅 Python sqlite3 to backtrader / Mutliple Data Feeds / Pandas DataFrame to Backtrader (5) | 2020.01.07 |
|---|---|
| Python으로 추세추종(모멘텀) 전략 백테스팅 (3) | 2020.01.02 |
| Python,BS4 Naver Finance 국내 증시 기초 Data 수집 - 2 (25) | 2019.12.16 |
| Python,BS4 Naver Finance 국내 증시 기초 Data 수집 - 1 (16) | 2019.12.15 |
| Python, Backtrader로 전략검증, RSI 이용한 매매 전략 백테스팅(BackTesting) (2) | 2019.12.08 |




댓글